Introduction to Redis - Part-1
08 Jun 2021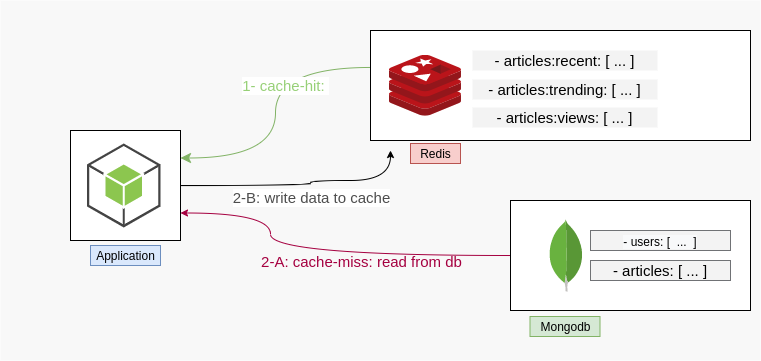
Introduction to Redis:
This a 3 parts article introducing Redis and how it can be used to solve different problems. The first part I’ll use Redis to cache the landing page database query.
The second part is another use case where I’ll use Redis to calculate most-viewed articles and retrieve them efficiently without bothering the database too much.
Part-3 I’ll refactor the code introduced in the previous parts.
All the examples are implemented in a multi-user blog I made while learning Node.js (Express.js). Remember this is only for learning purposes and not by anyway the most efficient way to serve blogs.
Part 1: Redis for caching
Redis is defined as in-memory data-structure and it’s well known for being amazingly fast. Before start writing code first thing you should know exactly what data-structure is most convenient to solve your problem. To make this decision we need to know what are the operations your application will frequently needs to run on the data eg. reading, inserting, searching. Redis commands docs explains the complexity (cost) of each command that you’ll use to manipulate the data. Having these info in mind we can utilize Redis to boost the back-end performance.
Query caching:
Check the controller code below that renders the most recent articles:
Instead of querying mongodb on every request, we will cache the result on first read. There is a little bug here, the query actually is not sorting the articles, it should be
Article.find({}).populate('author').sort({ createdAt: -1 })
For this it makes sense to use a data-structure that’s prioritized for sorting, like the sorted set, every member in the list has an associated score value for sorting which I set to the article’s createdAt attribute.
I’ve seen some articles that extends the mongoose query object and set the code responsible to deal with caching in a pre-query hook, but It’s kind of complicated and very error prone esp if you are not comfortable with object’s prototype inheritance in Javascript, even though it’s less repetitive. Another downside with this pattern is that it’s very coupled with the database engine you are using.
I opted to separate the caching-related code from the persistence layer “the db models” to have more clear responsibilities on each layer, and also to be more explicit about how we are accessing data “from where” without hidden code in the ODM. So I’ve created the following module access.js to manage how we retrieve data from the persistence storage. In contrary to controllers’ code, access.js knows about the caching and will implement the logic that answer the questions “should we read from cache or db?”, “should we write to cache first or db?” these concerns known as “the caching strategy”.
Before everything we need to set-up a client and connect to Redis server:
Redis client doesn’t support promises yet, so I wrapped it in an async function that returns a promise so callers can await on it. In next articles I’ll refactor this with promisify.
Line 13 defines the key that’s used to store recent-articles on Redis. Line 17, the command zrevrange is used to return the articles list ordered from highest to lowest, since the score is a timestamp this means we get the most recent articles. For now it returns all of them, but it shouldn’t, we should use pagination.
As I said we should pay attention to the cost, zrevrange call has a time-complexity of O(log((N) + M)), with M being the retrieved items’ length, it’s fast!.
Notice on line 21, the data that’s retrieved is string we need to parse and convert it back as as an Articel model instance.
Line 17, we call zadd to insert an article into the list, notice we need to stringfy it first. This call has a O(log(N)) cost, so both reading and writing can scale very well.
The caching strategy i’m using is called Cache-Aside as implemented in getRecentArticles(). It’s simple, getRecentArticles() first checks Redis for articles, if it is empty (or unreachable at all), then: fallback to the database (fetch fresh data), then cache the data for subsequent reads.
Last step, now we can use this interface in the home controller:
Notice how we didn’t need to change much on this module. The contoller doesn’t know or care where the data is comming from, it’s not its responsibility.
Data consistency
Whenever you are using caching you must pay attention to data-consistency between the cache and the database. For example getRecentArtilces() will retrieve invalid data if one user submitted a new article.
Now one obvious way to mitigate this is to update the cache whenever a user submits or edits an article, OR .. we can serve the staled data for more 5 minutes then just erase the cache, call it a day and hope no user will notice that the recent articles list didn’t contain articles posted in the last 5 minutes ? :), I also hope you can see where i’m going with this.
This is exactly what I’ve done in line 28, the recent’artilces data is erased from Redis every 15 seconds, assuming we have a very high rate of new posts and not just me with my “hello world”, “test test” articles :).
If your application is not very critical about data-consistency you can just set a TTL -time to live- on data to expire the cache.
Otherwise, if data consistency is very critical for your app to properly function, then maybe you should use a different strategy.
Redis as a sessoin store:
This not about caching but worth mentioning, Redis is also considered the go-to solution for user’s session. Performance wisely you don’t want to execute a query on every user’s interaction, and if the client’s session is changing a lot that is going to be a serious performance damage.
Load testing:
Finally I tested the impact of the changes I introduced -caching + session store- by running a load test using apache-benchmark. These results are from the landing page only.
-
Testing results before using redis:
These are the server throughput readings, I ran the test with 500 request and different concurrency levels. Notice how the throughput was degrading before using Redis
# conccurent req. Before Redis After Redis 100 163.41 303.83 120 146.15 336.46 160 137.31 324.15 200 129.90 335.71
Source code:
Here is the complete project source code:
Guide lines:
Finally a general guide lines and the “take away” from this experiment :
- Identify the queries you want to cache.
- Choose convenient data structure optimized for the operation you need (time complexity eg.
O(1)access time, sortingO(log(N)), .. etc) - Keep data consistent. (
TTL, Write through, .. . )